Contents
Contents
Writing a compiler can be challenging and fun. It's fun if you simply take it up as an exercise to learn about lexing, parsing and code generation. Not so fun if you try to implement an actual general purpose language in all it's glory.
Check out this repo to see how I made a simple C compiler
https://github.com/RohitRTdev/simc
To keep this process enjoyable, we will only be building a C compiler that supports a subset of the language features. For more info on the exact features implemented, please visit the repo. With that in mind, let's get onto it.
To write any compiler, we need to do 3 main tasks
To understand these 3 processes, let's first see what we are even trying to do. Whenever faced with a complex task, take a simple example first and see how the solution looks for that case alone, and then work on generalizing it.
Let's consider the code:
int a = b + c * d++ - *m;
How do we generate the code for this above statement. Before even answering this question, we need to first ask ourselves what architecture do we want to generate code for. I have decided to use the famous x64 / AMD64 architecture since it is the most widely used one in consumer PC's and laptops.
Now that we've decided the arch, let's see how the assembly for the code snippet above looks like.
x64 asm att syntax
//d++
movl -12(%rbp), %ebx //Load 'd'(assume it's stored at stack location rbp-12)
addl 1, -12(%rbp) //Increment 'd'
//c * d++
movl -8(%rbp), %eax //Load 'c'
imull %ebx, %eax // Signed multiply c * d++, now res0 = c * d++
//*m
movq -24(%rbp), %rbx //Load 'm'(We're loading into rbx since pointer is 8 bytes)
movl (%rbx), %ebx //Dereference pointer 'm', so res1 = *m
//sub res1 from res0
subl %eax, %ebx // Now res2 = res0 - res1
//b + res2
addl (%rbp), %ebx // This gives us the final result
//a = final_result
movl %ebx, -28(%rbp) //Store final result at 'a'
Variables b, c and d are assumed to be of type int and m is assumed to be of type int* .
Notice a few things here. First the variable's location. In C, variables are mostly stored in the stack, and it grows downwards in x64 arch. This is not the case always though (variables could also be located in static memory or heap). Also notice the offsets at which the variables are stored. They are allocated in such a way that all the variables are aligned on their natural boundary( int variables are aligned on 4 byte boundaries and pointers are aligned on 8 byte boundaries).
Now that we've generated the code, let's see how to make our compiler do this. To perform this, what should we do first?
The compiler will only be given an input file, which contains a huge string. We need to make sense of this string, i.e convert it into symbols that the C language understands. This is where step 1 comes in, Lexing. In this step, we break the input set of characters into tokens that our compiler understands.
After lexing, we should generate a list of tokens from our input string
token1: Type:keyword, symbol:int
token2: Type:Identifier, symbol:'a'
token3: Type:Operator, symbol:'='
token4: Type:Identifier, symbol:'b'
token5: Type:Operator, symbol:'+'
token6: Type:Identifier, symbol:'c'
token7: Type:Operator, symbol:'*'
token8: Type:Identifier, symbol:'d'
token9: Type:Operator, symbol:'++'
token10: Type:Operator, symbol:'-'
token11: Type:Operator, symbol:'*
token12: Type:Identifier, symbol:'m'
All of the lexer code is included in the lexer.cpp file under src/simcc. It simply iterates through the list of characters and tries to generate a token object. This object is defined in token.h header file under include/core folder.
The logic to generate this is implemented using a simple lookahead parser. This means that we need to atmost look one extra token to the right, before we can decide what the token is. The lexer and the parser are implemented as state machines. Each state tells the lexer how to process the current token and about how to reduce it (That is figure out what this token is).
C++
if(state == LEXER_START) {
sim_log_debug("In state LEXER_START. Searching for operator token.");
switch(ch) {
case ';': op = SEMICOLON; break;
case '{': op = CLB; break;
case '}': op = CRB; break;
case '~': op = BIT_NOT; break;
case '*': op = MUL; break;
case '/': op = DIV; break;
case '%': op = MODULO; break;
case '^': op = BIT_XOR; break;
case '(': op = LB; break;
case ')': op = RB; break;
case '[': op = LSB; break;
case ']': op = RSB; break;
case ',': op = COMMA; break;
case '!': {
state = EXTENDED_OPERATOR_TOKEN;
prev_op = NOT;
break;
}
case '+': {
state = EXTENDED_OPERATOR_TOKEN;
prev_op = PLUS;
break;
}
case '-': {
state = EXTENDED_OPERATOR_TOKEN;
prev_op = MINUS;
break;
}
case '&': {
state = EXTENDED_OPERATOR_TOKEN;
prev_op = AMPER;
break;
}
case '|': {
state = EXTENDED_OPERATOR_TOKEN;
prev_op = BIT_OR;
break;
}
case '<': {
state = EXTENDED_OPERATOR_TOKEN;
prev_op = LT;
break;
}
case '>': {
state = EXTENDED_OPERATOR_TOKEN;
prev_op = GT;
break;
}
case '=': {
state = EXTENDED_OPERATOR_TOKEN;
prev_op = EQUAL;
break;
}
default: {
state = LOOKAHEAD_FOR_CONSTANT;
}
}
}
The lexer starts at state LEXER_START. It checks if the given character(ch) is an operator. Most of the operators can be determined using just one character such as '*' or '~'. However, certain operators need further processing. This is why for certain other operators we go to EXTENDED_OPERATOR_TOKEN state. This state terminates and goes back to LEXER_START once it has determined the operator it is looking for by fetching the next character.
An example of such a character is '++'. When lexer fetches the first plus, it cannot immediately reduce that token, and can only do so once it has determined the next character (If the next character is a '+', then it gets interpreted as '++' otherwise just a single '+').
Once a particular token is determined, a token object is generated. The token object is declared as follows.
C++
struct token {
private:
token_type type;
token_sub_type sub_type;
size_t position;
bool is_keyword_data_type() const;
public:
std::variant value;
template
token(token_type _type, const T& val) : type(_type) {
value = val;
position = global_token_pos - 1;
}
token(token_type _type, token_sub_type _sub_type, const std::string& num) {
type = CONSTANT;
sub_type = _sub_type;
value = num;
position = global_token_pos - 1;
}
token(token_type _type, const char& val) {
type = CONSTANT;
sub_type = TOK_CHAR;
value = val;
position = global_token_pos - 1;
}
}
This token class has been simplified and not all fields displayed in this are integral to the conceptual understanding of the lexer. It is pretty self explanatory and stores information on what type of token it is (KEYWORD, OPERATOR, LITERAL etc) along with the value of that token. For example, if it is a string literal, then what is that literal.
Once all characters within the file are processed, the final token stream is passed on to the parser stage.
Parsing involves taking the input stream we had earlier and producing an abstract syntax tree(ast). The ast is a simple tree structure that tells the compiler in what order we must perform the operations listed.
Below picture shows the ast of the previous expression that our compiler generates.
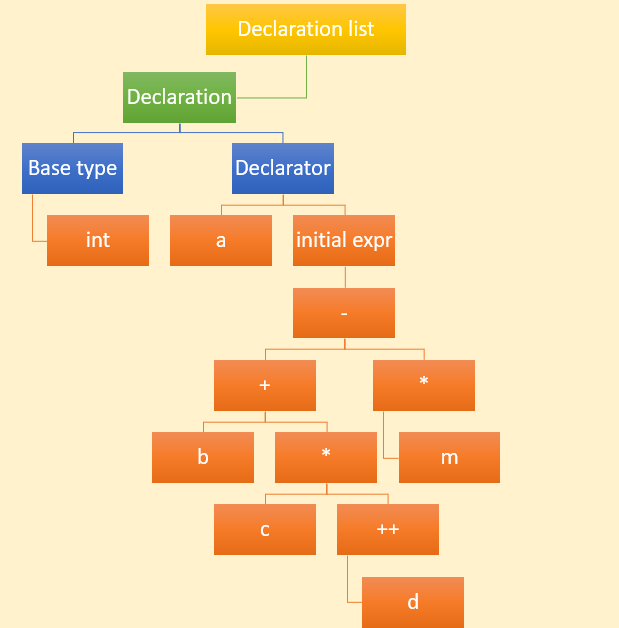
A declaration list contains multiple comma separated declarations. A declaration contains a declarator. A declarator could contain an identifier (it's optional since abstract declarators doesn't contain identifier). Declarators could also contain modifiers (such as pointer or array declarator). Our case is a very simple declarator that contains only an identifier (In C parlance, this is called an unmodified type).
The definition that I gave above could also be condensed into a notation as follows.
Taken from msdn website
declarator:
pointeropt direct-declarator
direct-declarator:
identifier
( declarator )
direct-declarator [ constant-expressionopt ]
direct-declarator ( parameter-type-list )
direct-declarator ( identifier-listopt )
pointer:
* type-qualifier-listopt
* type-qualifier-listopt pointer
type-qualifier-list:
type-qualifier
type-qualifier-list type-qualifier
The above definition is what is known as grammar. Although this is only showing the grammar (structure) of how declarations in C are laid out. Using this notation, we can describe all kinds of constructs within that language. It consists of two tokens, terminal and non-terminal. Terminal tokens are those which cannot be split further into simpler tokens. For example, type-qualifier (static, extern, auto, register) is a terminal token whereas declarator is a non terminal token.
You don't have to write a parser from scratch necessarily. There are tools such as bison, which will generate files written in C that implements a state machine which will parse your grammar. You simply need to give it the rules for your grammar, and it will generate the files for you.
However, simc uses it's own parser written from scratch. It is simply a state machine. State machines are abstract structures that allow us to visualize the flow of the state of a machine given a set of inputs. Each state is described by what kind of input it takes, and which state it proceeds to after getting that input. For the sake of this tutorial, we'll proceed with a simplified form of the C expression. The grammar for it is as follows.
Simplified expression grammar for C (BNF notation)
<expr> ::= <expr> binary_operator <expr>
<expr> ::= <expr> postfix_operator
<expr> ::= unary_operator <expr>
<expr> ::= identifier
<expr> ::= constant
Let's try parsing expressions with the above grammar. Our parser uses states which has only 2 pathways. Yes/No. Each state has a yes token. If the state machine finds that the current token is equal to the yes token, then we proceed to a given state, otherwise we proceed to the next state. The point to be noted here is that, we could have designed a state machine where a given state could have proceeded into more that 2 states but we chose to restrict it to just 2 states. The reason for this design will be clear in a second.
Let's take a look at a simple state machine that parses this table
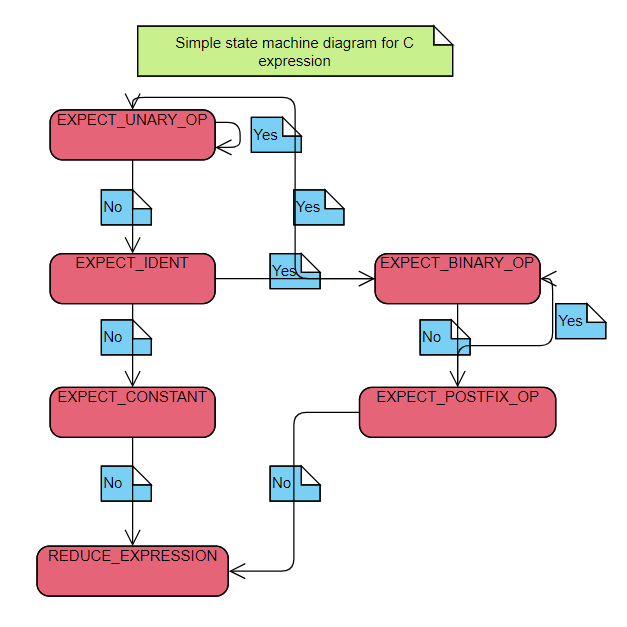
We start out by fetching tokens one by one from our token stream. Our start state in this case will be set to EXPECT_UNARY_OP. For each token, our parser checks if the token happens to be what the state mentions. If it is that token, then we go to the yes state. If it's any other token we proceed to the no state. This means that if the first token is a unary operator, then we proceed to state EXPECT_UNARY_OP, otherwise we proceed to state EXPECT_IDENT.
Within our parser, we define states like so
C++
static void parse_expr() {
//At start of expression
parser.define_shift_state("EXPECT_EXPR_UOP", EXPECT_EXPR_UOP, &token::is_unary_operator, EXPECT_EXPR_VAR, create_ast_unary_op);
parser.define_shift_state("EXPECT_EXPR_VAR", EXPECT_EXPR_POP, &token::is_identifier, EXPECT_EXPR_CON, create_ast_expr_var);
parser.define_shift_state("EXPECT_EXPR_CON", EXPECT_EXPR_POP, &token::is_constant, EXPECT_EXPR_LB, create_ast_expr_con);
parser.define_shift_state("EXPECT_EXPR_LB", EXPECT_EXPR_UOP_S, &token::is_operator_lb, EXPECT_EXPR_RB, create_ast_punctuator, nullptr, LB_EXPR_REDUCE);
//After an expression
parser.define_state("EXPECT_EXPR_POP", EXPECT_EXPR_POP, &token::is_postfix_operator, EXPECT_EXPR_BOP, false, reduce_expr_postfix);
parser.define_state("EXPECT_EXPR_BOP", EXPECT_EXPR_UOP_S, &token::is_binary_operator, EXPECT_EXPR_FN_LB, false, reduce_expr_bop);
parser.define_shift_state("EXPECT_EXPR_FN_LB", EXPECT_EXPR_UOP_S, &token::is_operator_lb, EXPECT_EXPR_LSB, create_ast_punctuator, nullptr, FN_CALL_EXPR_REDUCE);
parser.define_shift_state("EXPECT_EXPR_LSB", EXPECT_EXPR_UOP_S, &token::is_operator_lsb, EXPECT_EXPR_RB, create_ast_punctuator, nullptr, ARRAY_SUBSCRIPT_REDUCE);
//Terminal components in an expression
parser.define_special_state("EXPECT_EXPR_RB", &token::is_operator_rb, reduce_expr_rb, EXPECT_EXPR_RSB);
parser.define_special_state("EXPECT_EXPR_RSB", &token::is_operator_rsb, reduce_expr_rsb, EXPECT_EXPR_SC);
parser.define_special_state("EXPECT_EXPR_SC", &token::is_operator_sc, reduce_expr_stmt, PARSER_ERROR,
"Expected expression to terminate with ')' or ',' or ';'");
//States that start an expression but appear after an existing expression
parser.define_shift_state("EXPECT_EXPR_UOP_S", EXPECT_EXPR_UOP_S, &token::is_unary_operator, EXPECT_EXPR_VAR_S, create_ast_unary_op);
parser.define_shift_state("EXPECT_EXPR_VAR_S", EXPECT_EXPR_POP, &token::is_identifier, EXPECT_EXPR_CON_S, create_ast_expr_var);
parser.define_shift_state("EXPECT_EXPR_CON_S", EXPECT_EXPR_POP, &token::is_constant, EXPECT_EXPR_LB_S, create_ast_expr_con);
parser.define_shift_state("EXPECT_EXPR_LB_S", EXPECT_EXPR_UOP_S, &token::is_operator_lb, EXPECT_EXPR_FN_RB_S, create_ast_punctuator, nullptr, LB_EXPR_REDUCE);
parser.define_state("EXPECT_EXPR_FN_RB_S", EXPECT_EXPR_POP, &token::is_operator_rb, PARSER_ERROR, false, reduce_expr_empty_fn,
"Expected unary op, var, constant, '(' for start of expression");
}
The define_*_state functions will internally create a state object and will include it to the state machine. When the state machine is started, it goes through each of these states. The code shown above implements the state machine for a complete C expression, so you may see states that we didn't show in the picture. Now let's discuss about how the parser actually generates the ast.
The state machine includes a stack object which we call the parser stack. When we hit the yes condition in a state, it does one of three things.
Let us try to see how our parser would work for the simplified grammar I mentioned earlier.
When we walk through the states, we follow these additional rules.
Note: This is only valid for expression parsing.
binary_op_reduction:
Rule 1) If parser_token is not an operator, we don't do anything and simply fetch the next parser_token.
Rule 2) If parser_token is an operator, and it has lower priority than cur_token, then we stop our reduction, shift the cur_token and continue with the next state.
Rule 3) If parser_token is an operator, and it has higher priority than cur_token, then we invoke the combination rule for that operator according to rule 7-8, and then continue with the next parser_token.
Rule 4) If parser_token is an operator, and it has the same priority as cur_token, then we invoke rule 5 or rule 6.
Rule 5) If parser_token has LHS associativity, we combine the operator according to rule 7-8, and then continue with the next parser_token.
Rule 6) If parser_token has RHS associativity, then we stop our reduction, shift the cur_token and continue with the next state.
Rule 7) If we find a binary operator, then we create an ast node with the root of the node being the operator and left and right nodes of it being the nodes below and above it in the parser stack respectively. Push the newly created ast onto the stack.
Rule 8) If we find a unary operator, then we create an ast node with the root of the node being the operator and it's child node being the node above it in the parser stack. Push the newly created ast onto the stack.
Rule 9) If we hit the end of the stack, we stop reduction, shift the cur_token and continue with the next state.
postfix_op_reduction:
Create an ast node with the root being the postfix operator, and it's child being the top node on the parser stack.
Then push the ast onto the parser stack.
expr_reduction:
For each parser_token in parser stack:
if parser_token is binary_operator:
Reduce according to rule 7
if parser_token is unary_operator:
Reduce according to rule 8
When done with expr_reduction, we should only be left with one node in the parser stack. This node should represent the ast for our expression. All the code for the parser can be found under parser.cpp and the state-machine logic is implemented in state-machine.cpp.
Even though the section is titled evaluation, I will also be talking about code generation, as they are both closely tied to one another. Evaluation is the process of walking the ast we generated earlier, and then informing the code generator to create the type of code we need. At this point, it is imperative that we look at the overall architecture of our compiler.
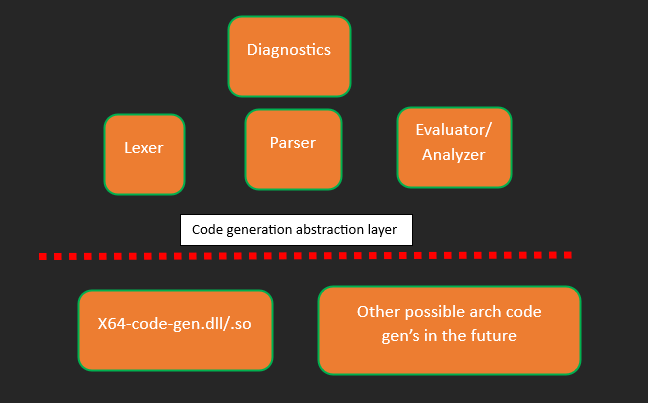
Lexer and parser modules have already been discussed in the previous sections. The main focus of this section would be the remaining modules, which is evaluator and code generator. The diagnostics module which I have included here is only for the sake of completeness. It is responsible for handling the error printing in the console when something goes wrong. This module is responsible for showing you the line number and the specific token which caused the issue when compilation fails. Since it is an implementation detail, I will skip the discussion regarding it.
We start by walking the ast (we use a DFS approach here). For each node, we call a specific handling function. For example, when we we visit a declarator node, the compiler adds the identifier to an identifier list along with it's properties, such as base type, modifiers, initial value etc.
For keeping the discussion brief and simple, let us consider how simc handles an expression node. The expression handler is written as a separate class. It's defined in evaluator.cpp file. Let's take a look at a couple of methods from this class which implements the backbone.
C++
void eval_expr::handle_node() {
expr = cast_to_ast_expr(expr_node);
if(expr->is_var()) {
handle_var();
}
else if(expr->is_con()) {
handle_constant();
}
else if(expr->is_operator()) {
auto op = cast_to_ast_op(expr_node);
auto sym = std::get(op->tok->value);
if(op->is_postfix) {
handle_inc_dec(sym, true);
}
else if(op->is_unary) {
handle_unary_op(sym);
}
else {
switch(sym) {
case EQUAL: {
handle_assignment();
break;
}
case AND:
case OR: {
handle_logical_op(sym);
break;
}
case COMMA: {
handle_comma_expr();
break;
}
default: {
handle_arithmetic_op(sym);
}
}
}
}
else if(expr->is_fn_call()) {
handle_fn_call();
}
else if(expr->is_array_subscript()) {
handle_array_subscript();
}
else {
CRITICAL_ASSERT_NOW("Invalid expr_node encountered during handle_node evaluation");
}
expr_node.reset();
}
void eval_expr::main_loop() {
while(!op_stack.empty() || expr_node) {
if(!expr_node) {
expr_node = fetch_stack_node(op_stack);
}
else {
if (hook())
continue;
if (expr_node->children.size()) {
auto child = fetch_child(expr_node);
op_stack.push(std::move(expr_node));
expr_node = std::move(child);
}
else {
handle_node();
}
}
}
}
eval_expr::main_loop implements the dfs algorithm using an iterative method. handle_node() calls the appropriate handler code method for a given node. This is pretty much all that the evaluator does. To understand the code generation process better, let us take a look at one of these handler methods.
C++
//Handles pointer dereference operation
void eval_expr::handle_indir() {
auto res_in = fetch_stack_node(res_stack);
//Must be a pointer
if(!res_in.type.is_pointer_type()) {
if(res_in.type.is_convertible_to_pointer_type()) {
res_in.type.convert_to_pointer_type();
}
else {
expr->print_error();
sim_log_error("'*' operator requires operand to be a pointer type");
}
}
//This will find the new type after applying dereference operator on it (If it's pointer to int, then it is resolved to int)
auto res_type = res_in.type.resolve_type();
if(res_type.is_void()) {
expr->print_error();
sim_log_error("'*' operator can only be used on a non void pointer type");
}
//This makes sure that we don't evaluate this operator during compile time (Like when it's used as part of an init expression in a global variable)
if(compile_only && res_in.is_constant && check_if_symbol(res_in.constant)) {
expr->print_error();
sim_log_error("'*' operator cannot be used to evaluate symbol during compile time");
}
expr_result res{res_type};
auto [base_type, is_signed] = res.type.get_simple_type();
res.expr_id = res_in.expr_id;
res.is_constant = res_in.is_constant;
res.constant = res_in.constant;
//If the dereference is within an "assignable context" then don't dereference, otherwise call the code generator
if(!(is_assignable() || res_type.is_array_type() || res_type.is_function_type())) {
if(res_in.is_constant) {
res.expr_id = code_gen::call_code_gen(fn_intf, &Ifunc_translation::fetch_from_mem, res_in.constant, base_type, is_signed);
}
else {
res.expr_id = code_gen::call_code_gen(fn_intf, &Ifunc_translation::fetch_from_mem, res_in.expr_id, base_type, is_signed);
}
}
//Save the result of this expression onto the working stack, which is were we save the results of computed sub-expressions.
res.category = l_val_cat::INDIR;
res.is_lvalue = true;
res_stack.push(res);
}
An expression of type * <expr> is going to be handled via the handle_indir() function. This function pops off one object (since dereferencing is a unary operation) from res_stack which is the stack where we push the results of the subexpressions. The type of this object is checked to see if it is a pointer type. If it's not a pointer type, then we see if it can be reinterpreted as a pointer type. Now if it's not an assignable context, then we call the code-generator. Assignable context is one where an operation is immediately followed by another operation which requires an L-value, such as '=', '&', '++' and '--' operators. We don't perform the dereferencing in this case as these operators require the address (In this case, address doesn't necessarily mean the location, but just refers logically to the container or variable itself). This is all there is to the evaluator, walk the tree, handle the node, call the code generator when appropriate, generate the result type and save the result on stack if required.
You may have noticed that we have an abstraction layer on top of our code generator in the architecture diagram. The code generator interface is provided in a virtual class and the actual implementation is generated as a separate library. This allows us to add another architecture without any modifications to code, other than the code-generator itself, thereby providing good layer of abstraction. The code generator interface exposes these functions. This is found in code-gen.h file.
C++
class Ifunc_translation : public Itrbase {
public:
//Declaration
virtual int declare_local_variable(std::string_view name, c_type type, bool is_signed, bool is_static) = 0;
virtual int declare_local_mem_variable(std::string_view name, bool is_static, size_t mem_var_size) = 0;
virtual int declare_string_constant(std::string_view name, std::string_view value) = 0;
virtual void init_variable(int var_id, std::string_view constant) = 0;
virtual void free_result(int exp_id) = 0;
virtual int create_temporary_value(c_type type, bool is_signed) = 0;
virtual int set_value(int expr_id, std::string_view constant) = 0;
//function
virtual int save_param(std::string_view name, c_type type, bool is_signed) = 0;
virtual void begin_call_frame(size_t num_args) = 0;
virtual void load_param(int exp_id) = 0;
virtual void load_param(std::string_view constant, c_type type, bool is_signed) = 0;
virtual int call_function(int exp_id, c_type ret_type, bool is_signed) = 0;
virtual int call_function(std::string_view name, c_type ret_type, bool is_signed) = 0;
//Assign variable
virtual int assign_var(int var_id, int id) = 0;
virtual int assign_var(int var_id, std::string_view constant) = 0;
virtual int assign_to_mem(int id1, int id2) = 0;
virtual int assign_to_mem(int id, std::string_view constant, c_type type) = 0;
virtual int fetch_from_mem(int id, c_type type, bool is_signed) = 0;
virtual int fetch_from_mem(std::string_view constant, c_type type, bool is_signed) = 0;
virtual int fetch_global_var(int id) = 0;
virtual int assign_global_var(int id, int expr_id) = 0;
virtual int assign_global_var(int id, std::string_view constant) = 0;
virtual int get_address_of(std::string_view constant) = 0;
virtual int get_address_of(int id, bool is_mem, bool is_global) = 0;
//Arithmetic operation
virtual int add(int id1, int id2) = 0;
virtual int add(int id, std::string_view constant) = 0;
virtual int sub(int id1, int id2) = 0;
virtual int sub(int id, std::string_view constant) = 0;
virtual int sub(std::string_view constant, int id) = 0;
virtual int mul(int id1, int id2) = 0;
virtual int mul(int id1, std::string_view constant) = 0;
virtual int div(int id1, std::string_view constant) = 0;
virtual int div(int id1, int id2) = 0;
virtual int div(std::string_view constant, int id) = 0;
virtual int modulo(int id1, int id2) = 0;
virtual int modulo(int id1, std::string_view constant) = 0;
virtual int modulo(std::string_view constant, int id) = 0;
virtual int bit_and(int id1, int id2) = 0;
virtual int bit_and(int id1, std::string_view constant) = 0;
virtual int bit_or(int id1, int id2) = 0;
virtual int bit_or(int id1, std::string_view constant) = 0;
virtual int bit_xor(int id1, int id2) = 0;
virtual int bit_xor(int id1, std::string_view constant) = 0;
virtual int bit_not(int id) = 0;
virtual int sl(int id1, int id2) = 0;
virtual int sl(int id1, std::string_view constant) = 0;
virtual int sl(std::string_view constant, int id) = 0;
virtual int sr(int id1, int id2) = 0;
virtual int sr(int id1, std::string_view constant) = 0;
virtual int sr(std::string_view constant, int id) = 0;
virtual int pre_inc(int id, c_type type, bool is_signed, size_t inc_count, bool is_mem, bool is_global) = 0;
virtual int pre_dec(int id, c_type type, bool is_signed, size_t inc_count, bool is_mem, bool is_global) = 0;
virtual int post_inc(int id, c_type type, bool is_signed, size_t inc_count, bool is_mem, bool is_global) = 0;
virtual int post_dec(int id, c_type type, bool is_signed, size_t inc_count, bool is_mem, bool is_global) = 0;
virtual int negate(int id) = 0;
//Type conversion
virtual int type_cast(int exp_id, c_type cast_type, bool cast_sign) = 0;
//Conditional operation
virtual int if_gt(int id1, int id2) = 0;
virtual int if_lt(int id1, int id2) = 0;
virtual int if_eq(int id1, int id2) = 0;
virtual int if_neq(int id1, int id2) = 0;
virtual int if_gt(int id1, std::string_view constant) = 0;
virtual int if_lt(int id1, std::string_view constant) = 0;
virtual int if_eq(int id1, std::string_view constant) = 0;
virtual int if_neq(int id1, std::string_view constant) = 0;
//Branch operation
virtual int create_label() = 0;
virtual void insert_label(int label_id) = 0;
virtual void branch_return(int exp_id) = 0;
virtual void branch_return(std::string_view constant) = 0;
virtual void fn_return(int exp_id) = 0;
virtual void fn_return(std::string_view constant) = 0;
virtual void branch(int label_id) = 0;
virtual void branch_if_z(int expr_id, int label_id) = 0;
virtual void branch_if_nz(int expr_id, int label_id) = 0;
virtual void generate_code() = 0;
virtual ~Ifunc_translation() = default;
};
This interface is resolved by the implementation files residing in the top level lib directory. Currently we only have the implementation for the x64 architecture. The code generator works by saving results in registers. In x64, we use these registers for storing general purpose data. rax, rbx, rcx, rdx, rsi, rdi, r8, r9. We also have the 32, 16 and 8 bit versions of these registers. When an operation is computed (say, add 2 variables), the result of this operation is saved in a register and an id is generated which tracks this. If another operation (say, mul 2 variables) is invoked, a new free register is picked and the result for this operation is saved in that. The id generated for this operation is returned back to the evaluator. The evaluator saves this id along with some other metadata as the result of that expression. If no register is available, then we free up a register by saving it's contents into the stack. This way we never run into a resource crunch.
Before adding variables, we must first declare them. It then generates a unique id for that variable. Later, when we want to perform an operation on that variable, we use this id to refer back to that variable. Let us see an example.
C++
auto tu = std::shared_ptr(create_translation_unit());
//Create a function (Name: test, ret_type:int, is_static:false)
auto fn = tu->add_function("test", C_INT, false, false);
//Create a non static unsigned int variable with the name "a"
//Note: The name that we give the variable here doesn't matter (This is only used by the evaluator), but the id it returns is what the code gen uses to refer to it
int var_id = fn->declare_local_variable("a", C_INT, false, false);
//param1: The function instance, param2: the method we want to call, remaining params: depends on the method that is called
//In this case param3: variable id, param4: constant that needs to be added with that variable
//Thus, this call logically means, perform "a-35" and the return value is an ID which refers to the result of this expression
int res_id = code_gen::call_code_gen(fn, &Ifunc_translation::add, var_id, "-35");
//Use this res_id in another expression or discard it
This is how the code generator is able to generate the code for any type of operation. For the sake of completeness, I'll show the code for the add function within the code generator. Note: Although, this is just how the x64 code generator is built, any other code generator that might be built into simc must also follow the same interface, where we use some sort of an ID mechanism to track results. This is important as the evaluator expects that type of behaviour.
C++
int x64_func::add(int id, std::string_view constant) {
insert_comment("add constant");
auto [reg1, _, type] = unary_op_fetch(id);
insert_code("add{} ${}, %{}", type, constant, reg1);
return reg_status_list[reg1];
}
unary_op_fetch(id) fetches the register associated with the id that the caller provided. It also returns the type of this variable.
So this concludes our foray into making a compiler. Although I have lead with examples from my own compiler and it was for the C language, the topics I discussed are applicable to any language, especially the lexer and parser sections. I didn't include too much detail into this blog as it would just be a bunch of implementation stuff, which might change in your case. My objective through this series was to just motivate the user to write their own compiler, and use mine as a reference material, or if you are interested, you may even contribute directly to this repo. Happy coding!😄